Make your code 2x faster with this simple Python library.


Celery is an asynchronous task queue framework written in Python. Celery makes it easy to execute background tasks but also provides tools for parallel execution and task coordination.
In the last post we touched upon basic principles of the Celery framework for Python.
You can check the last post here.
In this post we will discuss a way of architecting workflows in Celery and easily execute tasks in parallel.
When a lot of background tasks are involved it can be challenging to monitor and coordinate their execution. If the tasks are independent where order of execution is not important they can be executed in parallel with no consequences. Celery provides a way to both design a workflow for coordination and also execute tasks in parallel. Needless to say, parallel execution provides a dramatic performance boost and should be implemented when possible.
We will cover the following topics in this post:
- Retrieving results from background tasks
- Getting access to NewsAPI
- Task coordination with signatures
- Code
- Benchmarks
- Conclusion
By the end of this post, you will learn how to make almost any Python code faster and also how to structure the tasks in the process.
Let’s get on to it!
Retrieving results from background tasks
A background task can be defined as follows:
@celery.task()
def add(num1, num2):
return num1 + num2
A background task can be executed with the following syntax:
add.delay(4, 4)In order to retrieve the result of the task, we need to use a backend that allows Celery to store the results. There are many choices available but for this post we will use Redis.
Please note: Redis is not supported on Windows.
“Redis is an open source (BSD licensed), in-memory data structure store, used as a database, cache, and message broker” according to redis
Being an in-memory data store means read and write operations to Redis are particularly fast and makes it suited for tasks that require frequent read and write operations.
Linux guide for installing Redis.
For MacOS you can install Redis using homebrew.
Open a terminal and run:
brew install redisThen start the service with:
brew services start redisFor checking the service is running you can run:
brew services listA Celery instance can now be defined like this:
from celery import Celery
celery = Celery(
'calc',
backend='redis://localhost',
broker='pyamqp://guest@localhost//'
)The result of a background task can easily be retrieved with get() like this :
res = add.delay(4, 4)
res.get()
>> 8Getting access to NewsAPI
For the purposes of the tutorial, we need to retrieve data from an API call. We will be retrieving data from NewsAPI. You can register to get an API key from here.
Once you are registered you can view the documentation for the top headlines API call here. We will be using the top headlines endpoint and call it with a single country code name at a time.
Suppose we need to get top headlines from five countries. Instead of making five sequential calls it would be much faster to speed up the process by parallelizing the calls. But first, we need to look at signatures in Celery and a way to coordinate the results with the coord function.
Task coordination in Celery
“A signature wraps the arguments, keyword arguments, and execution options of a single task invocation in a way such that it can be passed to functions or even serialized and sent across the wire.” from Celery
Basically, signatures allow us to create and pass around references to Celery task objects.
This means we can do something like:
task = add.s(2, 2)Then we can simply invoke the function with delay() and call get() on it like before:
res = task.delay()
res.get()
>> 8Now you may be wondering why we need signatures at all. Signatures allow us to chain together commands and use workflow functions provided by Celery. Suppose we want to call add() multiple times in parallel and store the results. How would you go about doing that? Without signatures there is no way to keep a reference to a Celery task object.
The group function in Celery takes signatures as arguments and executes them in parallel, storing the results in a list. If we wish to execute add() calls in parallel we can do it with group() like so:
g = group(add.s(1, 1), add.s(3, 3))
res = g()
res.get()
>> [2, 6]Another useful function is coord(). This is similar to the group() command but allows us to define a callback. So instead of returning with a list of results, a callback function gets called with the list of results as argument. We define the callback function ourselves. The callback function gets called when all tasks have been executed. This means we do not have to keep track of which task is still running and whether all are finished or not.
The coord() function is very useful in cases where results have to be manipulated after getting them. For instance, if results of previous tasks have to be merged to generate a PDF report. Or if data retrieved from several API calls needs to be merged.
We will now retrieve top headlines from the NewsAPI in parallel and aggregate the results of the calls.
Let’s code!
If you are interested you can check the full list of workflow functions provided by Celery here.
Define the Celery app
Make sure you replace <API_KEY> with the API key in your newsAPI account.
We define a Celery app and then define two Celery tasks with the @ notation. In getNewsData we execute a simple GET request to retrieve top headlines from the country supplied as argument. This is the function that will be parallelized.
We want to retrieve the results of all the calls and concatenate them. For this, we define genReport to act as a callback function. In genReport we are simply converting the JSON objects into Pandas dataframes so that they can easily be concatenated. Once they are concatenated, we reset the index to avoid JSON casting errors and then return the concatenated dataframe as a JSON. The return type of Celery task functions must be JSON serializable which is why we cast back to JSON.
Define API
Remember to replace <API_KEY> with your API key.
We get the list of countries we want to retrieve news from and then create a list of task signatures. Each signature function is a reference to the getNewsData task with a country supplied as argument. The list of signature functions is passed as an argument to the coord function. Finally, the genReport function is passed as a callback function.
The chord function will execute the tasks in parallel and then call genReport with a list of the results.
Test and Benchmarks
Great! Now let’s test the code and make sure everything is in order.
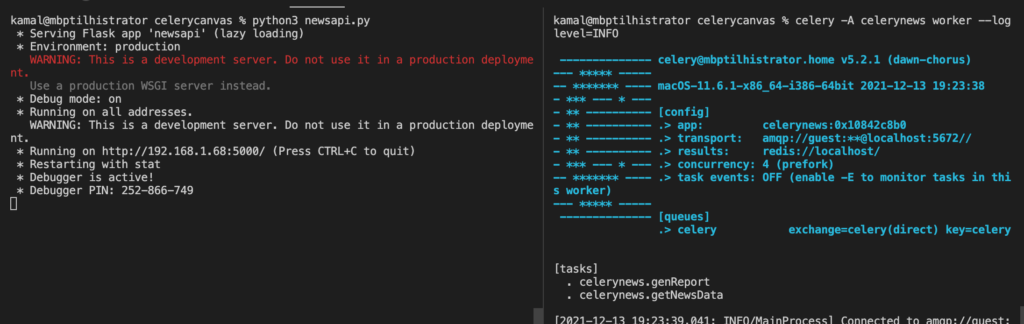
Make sure the redis service is running. Open a terminal window in the project root and then run the Flask app with:
python3 newsapi.pyNext, open a new terminal windows and run the Celery app with:
celery -A celerynews worker --loglevel=INFOEverything should be running like so:
Let’s call the API using Postman and see if it works!
We encode the data as a JSON object passing a list of countries specifying each country using its country code. Make sure you select POST as the request type and insert the correct url: http://0.0.0.0:5000/api/send
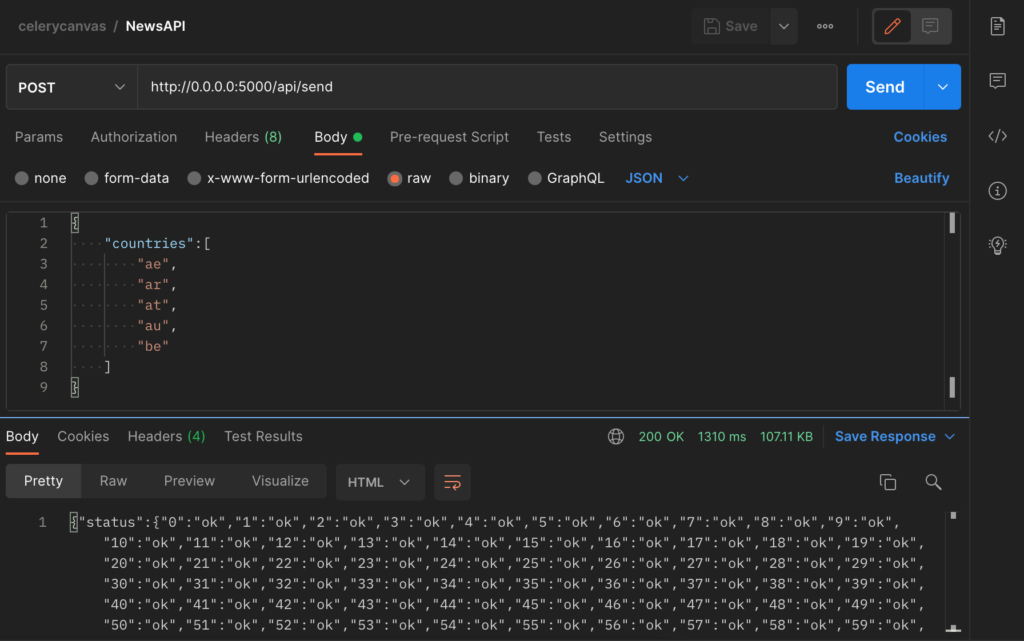
Hit send and you should see some response after a second or two.
I thought it would be interesting to see how much faster this parallelization actually is.
There is some commented code in the newsapi.py code file titled “Slow version”.
You can put the code under “Fast version” in comments and comment out the code under “Slow version”.
Save the file after commenting and Flask will automatically restart the web server.
We can now duplicate the tab in Postman we used earlier and hit Send once again.
You will notice it takes slightly longer to get a response. We can check the upper right corner of the response window in Postman to check how much time the response took. If you compare this to the fast version you will notice it is about 1.5 times faster.
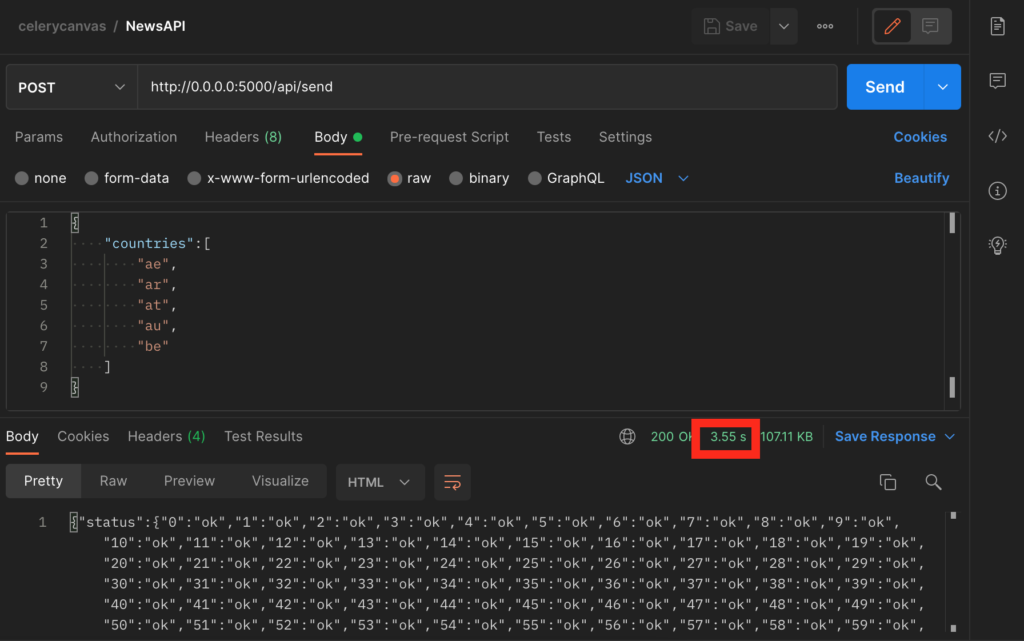
In my case, the parallelization using the chord function resulted in code that was more than 2.5 times faster than if I had not used it. That is quite a significant performance boost given that only 5 API calls were involved. For a greater number of calls the performance boost would be even greater as response time will grow linearly if calls are sequential.
More than just API calls
Hope you enjoyed the content of this article!
We have seen how to retrieve results of background tasks using Redis as a backend store for Celery. Furthermore, we saw the use of signatures in Celery and how to coordinate and parallelize tasks using built-in Celery functions such as chord and group.
This topic is super interesting and useful. I believe it deserves more than just a single post. So before leaving I would like to touch upon some more use cases.
I used API calls in this tutorial due to ease of demonstration. However this technique can be used for a plethora of different and varied cases. As long as the individual tasks are unordered that is – if the order of execution does not matter, they can be parallelized.
The following three cases come to mind:
- Machine learning tasks – training multiple different models on the same dataset.
- Web scraping tasks.
- Automation scripts
In the first case, the different models can be trained independently. Validation scores can then be calculated based on the results that are accumulated. The model that gives the best validation score can then be saved for future use. In this case the chord function would be ideal to use.
In the second case, multiple websites can be scraped independently and the results stored. If the results just need to be stored without further manipulation we can use something like the group function.
Lastly, the various functions available in Celery can be used in automation scripts. Automation scripts often require a bunch of repetitive tasks that need to be executed and coordinated. Using the built-in Celery workflow functions for writing the scripts would result in cleaner and more maintainable code.
That’s it for this post. Hope you learnt something. Until next time!
You can also find me on LinkedIn here: Muhammad Haseeb Kamal | LinkedIn